PRG036 pisemka 2007-06-05
Zadani
(pocty bodu za kazdou otazku jsou uvedeny v hranatych zavorkach za znenim otazky)
1. Oznacte spravne odpovedi. [1]
- (a) XPath 2.0 je podmnozinou XQuery 1.0
- (b) XPath sdili jen cast vyrazovych prostredku s XQuery
- (c) XQuery umoznuje uzivateli deklarovat funkce
- (d) XQuery bylo mineno jako nahrada XSLT
2. Jmenujte alespon 4 prvky jazyka XML schema, ktere umoznuji propojit XML schema s jinym XML schematem. [2]
3. Uvazujte schema podobne jako je na obrazku 1 a popiste slovne vyznam nasledujicich XPath vyrazu. Pro usnadneni nepouzivejte terminy jako uzel ci element, ale spise khiha, nadpis atd. [4]
- (a) //kniha/nadpis
- (b) //kniha/*/sekce[2]
- (c) kapitola[nadpis]
4. Zaskrtnete to, co je v soulady s pravidly XSLT. [1]
- (a)
<xsl:template match = "ahoj" >
akce
</xsl:template>
- (b)
<xsl:template if test="podminka">
akce
else
jina akce
</xsl:template>
- (c)
<xsl:template when test="podminka">
akce
</xsl:template>
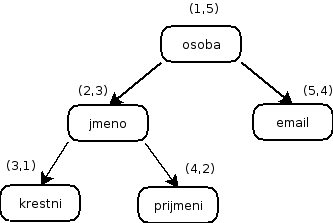
5. Pro dany XML dokument nakreslete strom a demonstrujte ohodnoceni jeho uzlu podle algoritmu structure-centered mapping. Vysvetlete vyhody a nevyhody tohoto algoritmu. [3]
<osoba>
<jmeno>
<krestni>Karel</krestni>
<prijmeni>Nemec</prijmeni>
</jmeno>
<email>karel.nemec@comp.cz</email>
</osoba>
6. Element <kniha> neni korenovy element, ale pouze soucast nejake hierarchicke struktury dokumentu "kniha.xml". Kazda kniha ma pouze jednoho autora, atribut email u elementu autor je nepovinny. Aktualni kontextovy uzel je rodic elementu kniha, ktery je zobrazen na obrazku 1.
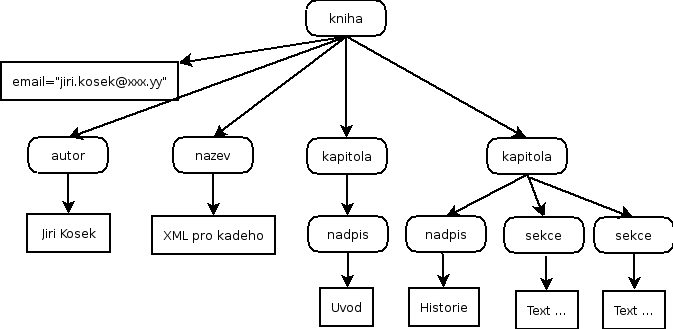
Napise XPath dotaz:
D1. Predchazejici uzly pred nadpisem 1.kapitoly elementu kniha. Vysledek vyznacte take v obrazku. [2]
7. D2. Napiste dotaz v jazyce XQuery ktery vrati pro kazdeho autora jeho jmeno v elementu <jmeno>, jeho email v elementu <email>. Tyto udaje se ve vysledku budou nachazet v elementu <autor> a cely vysledek bude vlozen v elementu <autori>. [3]
8. D3. Uvazujte stejny dotaz v XQuery jako v D2 pouze s tim rozdilem, ze pokud autor nema email pak v elementu <email> uvedte text "Nema emailovou adresu". [3]
Spravne odpovedi
Tyto odpovedi byly uznany v pisemce jako spravne:
1. Spravne je (a) a (c).
2. 4 pozadovane prvky jsou napr. include, import, redefine, any.
3.
- (a) kazdy nadpis kazde kapitoly, avsak pouze takovy nadpis, ktery je primym synem kapitoly
- (b) kazda druha sekce takova, ze jako prarodice ma element kniha
- (c) kapitola, ktera ma nadpis. Zde je vsak potreba zminit, ze zalezi na aktualnim kontextkovem uzlu, ve kterem se prave nachazime.
4. Spravne je pouze (a).
5. (Odpoved lze najit ve slidech s nazvem "Vztah XML databází k jiným databázovým systémům")
- Vyhody: Pro kazde dva elementy lze urcit jejich vzajemny vztah - jestli jeden je podelementem druheho ci naopak.
- Nevyhody: Fakticky nelze snadno aktualizovat. Pri aktualizaci je zapotrebi cely strom precislovat.
- Strom je zobrazen na nasledujicim obrazku. Ohodnoceni uzlu je dvojice hodnot, kde ta prvni odpovida preorder pruchodu stromem a druha postorder pruchodu.
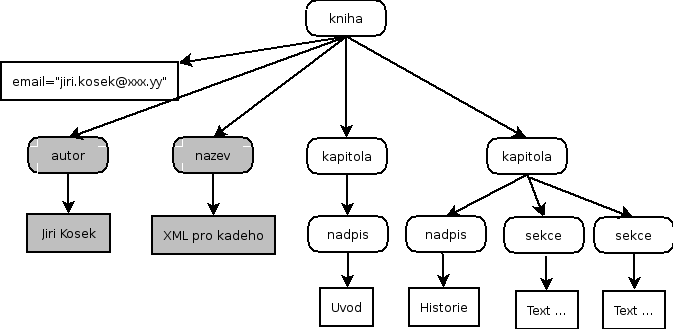
6. kniha/kapitola[1]/nadpis/preceding::*
7.
<autori>
{
for $kniha = doc("kniha.xml")//kniha
return
<autor>
<jmeno>{ $kniha/autor/text() }</jmeno>
<email>{ $kniha/@email }</email>
</autor>
}
</autori>
8.
<autori>
{
for $kniha = doc("kniha.xml")//kniha
let $email := $kniha/@email
return
<autor>
<jmeno>{ $kniha/autor/text() }</jmeno>
{
if (exists($email))
then <email>{ $email }</email>
else <email>Nema emailovou adresu</email>
}
</autor>
}
</autori>
Bodovani
Celkem bylo mozne ziskat 21 bodu, znamkovaci stupnice byla nasledujici:
- 19 - 21 → 1
- 18 - 17 → 2
- 16 - 15 → 3
- jinak za 4