Státnice I3: Syntax bezprostředních složek a frázové gramatiky
Tenhle soupis původně pochází ze zápisků z předmětu Úvod do formální lingvistiky Prof. Hajičové ze ZS 2007/8, byl ale přepracován na základě Wikipedie a skript Hajičová, Panevová, Sgall: Úvod do teoretické a počítačové lingivistiky I. -- Tuetschek 00:03, 22 Aug 2010 (CEST)
Frázové gramatiky
Bezprostřední složky
V Americké lingvistice se od 30. let minulého století prosazoval hlavně deskriptivismus, jehož hlavním představitelem byl L. Bloomfield. V něm šlo hlavně o klasifikaci a statistický popis distribuce prvků ve větě a jejich vztahů. Na základě distribucí odlišovali syntaktické
- endocentrické konstrukce, kde výskyt jedné z částí samostatně má stejnou distribuci jako celek, a
- exocentrické konstrukce, kde výskyt pouze některých částí není možný.
V syntaxi se uplatňuje strukturální přístup, konkrétně analýza bezprostředních složek, kdy věta dostává stromovou strukturu: celá věta se postupně dělí na složky, přičemž vždy nadřazená složka dominuje své podřízené (viz níže). Pro dělení do složek ale Bloomfield spoléhal na intuici a nezaváděl žádná pravidla. Navíc převažovala binární kombinace a dekompozice, takže bylo trochu složité najít závislost a stromy měly hodně „úrovní“.
Frázové stromy
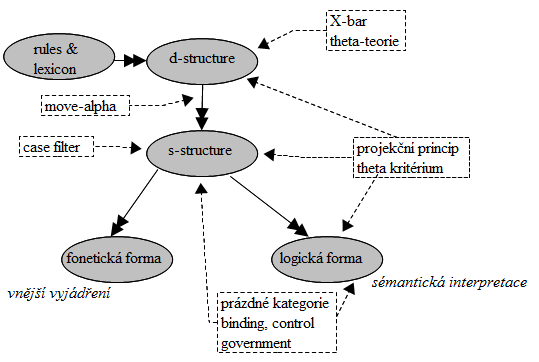
V teorii bezprostředních složek, stejně jako v nejrůznějších verzích Chomského transformační gramatiky, je věta reprezentovaná frázovým stromem, někdy označovaným jako frázový ukazatel. Uzly tohoto stromu odpovídají složkám -- frázím: každý uzel odpovídá určitému souvislému úseku věty. Vztah mezi uzly na vyšší a nižší úrovni je dominance -- úsek věty příslušící složce na vyšší úrovni je složením úseků příslušících složkám na nižší úrovni. V generativní gramatice lze takový strom chápat tak, že uzel na nižší úrovni vznikl použitím přepisovacího pravidla z uzlu na vyšší úrovni.
Formálně: frázový neboli složkový strom je pětice $ T = \langle N,Q,D,P,L\rangle\,\; $, kde:
- $ N\,\; $ je množina uzlů,
- $ Q\,\; $ je množina ohodnocení uzlů (gramatických kategorií),
- $ D \subset N\times N\,\; $ je relace dominance,
- $ P \subset N\times N\,\; $ je relace precedence (ostré částečné uspořádání, zaručující slovosled) a
- $ L: N\to Q\,\; $ je ohodnocovací funkce (přiřazení gram. kategorií uzlům)
A navíc platí následující podmínky:
- existuje jediný kořen stromu (daný relací dominance)
- relace $ D, P\,\; $ jsou antisymetrické
- strom splňuje podmínku projektivity (složky se nesmí částečně překrývat)
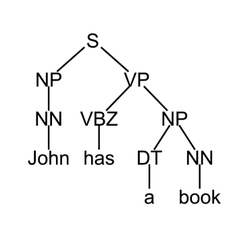
Složkový strom lze zapisovat buď jako stromové schéma (viz obrázek, možná je i varianta s kořenem nahoře), nebo pomocí "labeled bracketingu":
- [S [NP [NN John]] [VP [VBZ has] [NP [DT a] [NN book]]]]
Kvůli podmínce projektivity není možné zobrazit neprojektivní konstrukce, kde by se složky částečně překrývaly -- docházelo by ke křížení frázových hran vzhledem ke slovosledu a nešlo by nalézt správné uzávorkování. Příklad:
- I saw a man with a dog yesterday, which was a yorkshire terrier. Vánoční nadešel čas. Soubor se nepodařilo otevřít.
zápis: strom (obrácený nebo normální) / „labelled bracketing“
Začátky Transformační gramatiky
Chomský vycházel z tradice amerického deskriptivismu a frázových gramatik, ale přidával myšlenku, že nestačí jen jazykový jev pozorovat a popsat, že je třeba ho vysvětlit. Navíc akceptuje staré teorie univerzální gramatiky, tj. vrozenosti části jazykové kompetence, která je společná pro všechny jazyky. Idea transformací, uvedená deskriptivistou Z. Harrisem, byla pro spojení všech myšlenek velice vhodná.
Znalostí jazyka je pro Chomského znalost pravidel, použitých ke generování gramaticky korektních vět. Gramatičnost považuje za rozhodnutelnou, i když přiznává, že jde o idealizaci. Ve svých výzkumech spoléha na vlastní intuici, nesoustředí se na korpusy.
Jako cíl výzkumu nestanovuje poznání mentalních procesů tvorby vět, ale to, jak větu tvoří gramatika. Gramatika je podle něj nástroj, který z konečné množiny slov generuje nekonečný jazyk -- díky rekurzivitě (např. nepřímá řeč, "pes jitrničku sežral" a pod.), o které věřil, že je společná všem přirozeným jazykům.
Syntaktické struktury (1957)
V této knize Chomsky popsal první verzi své teorie a její aplikaci na angličtině. Představuje několik druhů generativních gramatik (které později shrnul do své slavné hierarchie) a na protipříkladech ukazuje, že ani regulární gramatiky, ani bezkontextové gramatiky nejsou schopné samy o sobě popsat přirozený jazyk. Bezkontextové gramatiky odpovídají bezprostředním složkám, ale generativní přístup (proti deskriptivnímu) je nový.
Chomsky zavádí transformační generativní gramatiku. Obsahuje bezkontextovou generativní gramatiku, ale navíc přidává ještě jeden krok tvorby vět -- transformace. Spolu s tím se přidává distinkce dvou úrovní:
- hloubková struktura (vytvářená generativní gramatikou)
- povrchová struktura (tvořená transformacemi z hloubkové struktury)
Gramatika pak sestává z následujících komponent:
- báze, sestávající z:
- lexicon (seznam slov podle druhů příslušných neterminálů, např. tranzitiva, intranzitiva ...)
- phrase structure rules (soubor pravidel ke generování vět, včetně doplnění terminálních symbolů, S --> VP NP / nepovinné části, bezkontextová pravidla)1
- transformational rules -- pravidla např. pro aktiv/pasiv, oznamovací větu a otázku atd. Vychází z toho, že některé struktury jsou úzce provázané a generativní pravidla pro ně by se duplikovala. Obsahují dvě podčásti:
- Strukturní analýza (na jakou část se aplikují)
- Strukturní změna (jak se provádějí)
- fonologický komponent -- regulární pravidla, přiřazující zápisům věty fonetické reprezentace
Při tvorbě vět se tedy nejprve použijí frázová (báze, vznik kernelové věty) a pak transformační pravidla (transformace jsou povinné nebo nepovinné, dochází i ke změnám významu).
Chomsky věřil, že je možné vyrobit pravidla, jejichž výstup budou korektní (anglické) věty. V této verzi teorie úplně vynechal sémantiku (zřejmě pod vlivem deskriptivismu), což kritizovali jeho studenti (J. J. Katz, P. M. Postal). To vede k dalšímu vylepšování.
Standardní teorie (1965) a její rozšíření v 60.--70. letech
Další verze, tzv. Standard Theory, shrnutá v knize Aspects of the Theory of Syntax obsahuje několik vylepšení. Nejdůležitější z nich je zavedení sémantiky, přičemž se tu (poprvé) objevuje odkaz na teorie univerzální gramatiky -- hloubková struktura jako sémanticky interpretovaný základ pro transformace.
Gramatika tu sestává z následujících částí:
- Syntaktická komponenta (obsahuje bázi a transformační komponentu)
- Sémantická komponenta (lexikon obsahující sémantické informace a projekční pravidla, která přiřazují syntaktickým stromům interpretaci)
- Fonologická komponenta
Generování vět potom vypadá následovně:
- Báze vygeneruje hloubkovou strukturu (používá už nejenom frázová, ale i transformační pravidla, slovník obsahuje syntaktické rysy, podle kterých lze transformacemi doplňovat slova za neterminální symboly)
- Sémantický komponent jí dodá významovou interpretaci
- Transformační komponenta z hloubkové struktury vytvoří povrchovou strukturu (transformace v této verzi nemohou měnit význam)
- Fonologická komponenta z ní vytvoří fonetickou intepretaci
Synonymní věty mají stejnou hloubkovou, ale jinou povrchovou strukturu, homonymní naopak. To odpovídá vztahu asymetrického dualismu, popisovanému v Pražské škole.
I tato verze teorie měla problémy, např. s větami jako:
- „Many men read few books“ a „Few books are read by many men“
Kdy obě nemají stejný význam. Stejný problém se v češtině ukazuje u aktuálního členění věty:
- „Mnoho lidí čte málo knih“ / „Málo knih čte mnoho lidí“
Chomského studenti argumentovali, že vybíráme-li význam z hloubkové struktury, pak tato musí být „hlubší“ než je tu navržené. Rozmíšky okolo podobných problémů vedly k rozštěpení teorie. Vznikla tak Generativní sémantika (G. Lakoff, J. McCawley, J. R. Ross), která obsahuje hlubší hloubkovou strukturu a transformace v ní nemohou měnit význam.
Interpretativní sémantika (rozšířená standardní teorie)
Chomského reakce na Generativní sémantiku byla, že zachoval stejnou hloubkovou strukturu (dále i d-struktura), ale sémantická interpretace se provádí nejen z hloubkové, ale i z povrchové struktury. Transformace tak mohou měnit význam. Odůvodňoval to hlavně distinkcí mezi presupozicí a fokusem, tj. zachycením aktuálního členění.
X-bar
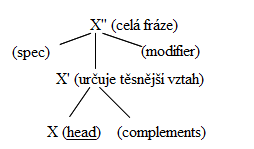

Na základě výzkumu nominalizací byla jako rozšíření standardní teorie uvedena teorie X-bar (podle značení $ \bar{X}\,\; $, které se ale často zjednodušovalo na $ X'\,\; $), vycházející z tzv. lexikalistické hypotézy, která tvrdí, že nominalizace není transformací. Naopak identifikuje univerzální strukturu frází (libovolných typů -- S, PP, NP, VP), díky níž nominalizace odpovídají větám. Ta má 2-3 patra: "bez pruhů" (nejnižší), "1 pruh", "2 pruhy" (nejvyšší), která obsahují následující prvky:
- phrase (maximal projection): celá fráze ($ X''\,\; $, $ XP\,\; $)
- head: na nejnižší úrovni, charakteristický prvek fráze (později „governing element“), předp., že jenom 4 kategorie slov můžou být hlava (N, V, Prep, Adj)
- specifier: doplněk fráze na vyšší úrovni, pre- nebo post-order (např. pro NP je to v angličtině člen)
- modifier (adjunct): volný doplněk $ X''\,\; $/ $ X'\,\; $, může jich být libovolný počet, v pre- nebo post-orderu – způsobuje rekurzi
- complement (argument): doplněk hlavy na nejnižší úrovni (povinný, úzký vztah), může jich být lib. počet (i nula), mohou stát před nebo za X
Dvě různé úrovně pro complement a modifier jsou vlastně prostředek k popsání blízkosti vztahu (complement x modifier), což se dá chápat jako přiblížení se závislostnímu popisu. Navíc existují některé drobné odchylky pro úroveň věty a pro PP, celek ale funguje jako univerzální schéma pro celé věty. Kvůli členům, předložkám atp. ale vychází dost složitě.
Podmínky pro transformační pravidla a stopy
Pro omezení síly transformací, které se ukázaly být příliš obecné, byly přidány podmínky na jejich aplikaci -- např. omezení jejiho rozsahu, později nazvané bounding, a zavedení traces (stop), což jsou v případě přemístění prvků transformacemi prázdné kategorie na původních místech, svázané s přemístěným prvkem. Při přechodu do fonetické reprezentace se uplatňují další pravidla a povrchové filtry, které částečně nahrazují podmínky na transformační pravidla.
Sémantická interpretace nyní probíhá přímo z povrchové struktury a to přes logickou strukturu. Odvození významu ze samotného povrchu ale nestačí a je nutné uchovávat další informace, proto byla v první polovině 70. let zavedena místo povrchové struktury tzv. decorated surface / shallow structure (s-struktura). Může obsahovat např. údaje o tom, že „sloveso je tranzitivní“, nebo stopy po transformacích.
Teorie Principles and Parameters / Government and Binding
Tato teorie, popsaná poprvé v knize Lectures on Government and Binding (1981) se vyvinula ze Standardní teorie během 80. let. Je vedena snahou o lepší vysvětlení jazyka a rozvíjením myšlenek univerzální gramatiky. Chomsky zastával názor, že je vrozená nějaká jazyková schopnost, která je lidem společná (principy) a něco je naučené (parametry) – to dohromady dává schopnost mluvit mateřským jazykem.
- Př. princip -- „slova se dají přemísťovat“, parametr – slovosled konkrétního jazyka (constraint)
- Př. princip -- "věta musí mít subjekt", parametr - "vyjadřuje se subjekt povinně vždy?"
Jedním z postulovaných principů je strukturálnost jazyka. Chomsky dále trvdí, že struktura jazyka je právě X-bar. Základní schéma generování vět zůstává stále stejné, s několika vylepšeními. Mezi základní principy patří:
- Theta-role a cases
- Vztahy government, binding, bounding a control
Projection principle a theta-role
Tyto vlastnosti byly do gramatiky přidány, aby ve výsledku lépe odrážela lexikální vlastnosti jednotlivých slov.
Projection principle ve své podstatě tvrdí, že veškeré informace z lexikonu je třeba zachovávat během celého generování. Až do jeho zavedení byly lexikální informace při generování ignorovány. Formálně: reprezentace na obou rovinách splňují subkategorizace lexikálních jednotek, přičemž subkategorizace je omezení komplementů podle lexikální realizace hlavy fráze (např. kick vyžaduje NP, think povoluje celé S' (klauzi), discuss taky jen NP)2. Pro zachování informací v povrchové struktuře se opět používá "decorated surface".
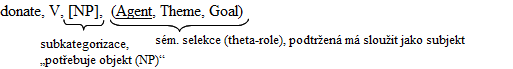
Subkategorizace se vztahují jak na gramatiku, tak na sémantiku, kde se nazývají theta-role (θ-role, tématické role). Každý argument (komplement) prvku (na každé úrovni) musí mít přiřazenu (právě jednu) theta-roli; každá theta-role je přiřazena právě jednomu argumentu (až na koordinaci). Řekneme, že $ A\,\; $ theta-označuje $ B\,\; $, když subkategorizuje pozici, na které se nachází $ B\,\; $ (a to může být buď v rámci fráze, jíž je $ A\,\; $ hlavou, nebo mimo ni (např. sloveso pro subjekt). Theta-role jsou svým způsobem navázání na teorii Cases C. Fillmora, z níž vychází idea pádového filtru (case filter) (každé NP musí mít přiřazený pád), který Chomský s theta-teorií spojuje.
Heslo v lexikonu tedy obsahuje dva druhy informací – syntaktické (subkategorizace) a sémantické (theta-role), jak je vidět z obrázku.
Command, government a binding
Vztahy command, government a binding spojují fráze ještě dalšími vztahy, než je dominance původních bezprostředních složek, takže umožňují složitější závislosti. Jejich základem je vztah command, ostatní dva jsou na něm postavené. Tento vztah umožňuje spojit i fráze, které na sebe přímo nenavazují. Existují dvě varianty:
- c-command -- $ A\,\; $ c-commanduje $ B\,\; $, když $ A\,\; $ nedominuje $ B\,\; $ a každý větvící se uzel nadřízený $ A\,\; $ je také nadřízený $ B\,\; $
- m-command -- zmírňuje podmínku na každou maximální projekci $ X''\,\; $.
Vztah government nastává, když:
- $ A\,\; $ je hlava fráze
- $ A\,\; $ m-commanduje $ B\,\; $
- mezi $ A\,\; $ a $ B\,\; $ není žádná bariéra (zpravidla maximální projekce)
Governující uzel potom určuje case (theta-roli) uzlů, které governuje.
- Př: Lze např. popsat, že sloveso „seem“ může být komplementováno slovy „as“, „to be“ -- a to může procházet napříc větou.
Z transformační komponenty, tj. z přesouvání frází a traces byl v nové verzi teorie vytvořen obecný princip move-α. Traces zachovávají theta-role (co-indexing) a cíle přesunu jsou omezené (jen subjekt, pozice adjunktu). Navíc podle teorie bounding (ohraničení) nelze přesouvat přes víc než jeden boundary node (ty jsou různé pro různé jazyky, v Angličtině S, NP):
- „the man whoi [S I think [S' that [S you said [S' that [S you had seen ei]]]]]“ -- OK
- „the man whoi [S I identified [NP the dog [S' whichj [S ej bit ei ]]]]“ -- nepřejde přes NP, tedy nekorektní!
Navíc se aplikuje pádový filtr, který vyřadí taková NP, které nejsou prázdná a nemají přiřazenou theta-roli (pád).
Vztah binding popisuje anaforicitu a reflexivitu, ale i např. subjekt infinitivu apod. $ A\,\; $ binduje $ B\,\; $, když:
- $ A\,\; $ governuje $ B\,\; $
- $ A, B\,\; $ jsou co-indexovány (tj. odkazují na to samé, jsou v anaforickém vztahu)
Existuje několik poddruhů tohoto vztahu, na které jsou další restrikce. Na vztahu binding je pak založená teorie control, která (slovníkově) klasifikuje slovesa, jež mají závislou infinitivní klauzi, podle toho, zda vyžadují, aby nějaké jiné jejich doplnění bylo koreferenční s podmětem infinitivu.
- decide, promise – anaforická relace se subjektem („John decided to go“ = John goes)
- persuade – anaforická relace s hl. objektem („John persuaded Max to go“ = Max goes)
90. léta -- Program Minimalismu
V 90. letech si Chomsky uvědomil, že teorie by měla nejen vysvětlovat, ale zároveň být ekonomická. Všechny teoretické nároky by měly být zachovány, i když se na povrchu neprojevují. Přišel tedy s novou teorií, která uvažuje jen dvě roviny popisu (interface levels):
- myšlenková doména, proces, objekt (logická forma) -- rozhraní mezi jazykem a kognitivní oblastí
- fyzická forma (fonetická interpretace) -- rozhraní mezi jazykem a fyzikální akustickou skutečností
Snaží se popsat jejich vztahy. Generování by mělo mít stejný cíl, tj. schéma teorie by mělo být interpretovatelné stejně jako dřív:
- Jsou použitá generativní pravidla. Znovu jde o generování, soustava filtrů ztratila důležitost -- věta se skládá operacemi merge a move.
- Potom se v tzv. bodě spell-out oddělí cesty logické a fonetické interpretace -- operace provedené do tohoto bodu jsou viditelné v obou strukturách, pozdější jsou už na sobě nezávislé.
Nová teorie je dost rozdrobená, navíc nový typ pravidel ve skutečnosti výsledné struktury dost roztahuje. Nové práce vycházejí v časopise „Linguistic inquiry“.
Další teorie s frázovou gramatikou
Cases

Tato teorie byla představena C. Fillmorem v roce 1968 jako reakce na to, že Chomsky zanedbává ve své původní teorii sémantiku. Vycházel z názoru, že hloubková struktura má být hlubší a obsahovat celý význam věty. Je ve své podstatě mnohem bližší evropskému závislostnímu přístupu, a ač používá frázovou gramatiku, uvažuje i o závislostním přístupu:
- struktura věty: bez přepisovacích pravidel, skládá se z modality a propozice
- case: pád, ale jde hlavně o význam, sémantickou funkci (deep case)
- Př. agentiv, lokativ (Chicago is windy), instrumentál, objektiv, dativ (John believed ... = experienced a belief)
- propozice: „jádro věty“ -- obsahuje sloveso (přísudek) a case phrases (tolik, kolik je potřeba – není binární), není VP, tedy jde rovnou o sloveso a jeho komplementy, z nichž každý má přiřazen case
- modalita: negace, modální sloveso, vid, čas
- case phrases: jsou přímo vázané na sloveso, obsahují case feature (pádový příznak) a NP (které mají stejnou strukturu jako X-bar, to pro Fillmora nebylo důležité)
- case frames: sloty slovesa pro vázání cases (něco jako valence), některé jsou povinné, některé ne
- existují závislosti – někt. cases musí být přítomny, když jsou přítomny jiné
- Př. break ((Ag) Instr) Obj) – je-li agent, je nutný instrument („John rozbil okno“ -- rozumí se „něčím“), je-li instrument, agent není nutný („Větev rozbila okno“)
Lexikálně funkční gramatika
Tuto teorii vytvořili Joan Bresnanová a Ron Kaplan na přelomu 70. a 80. let. Zdůrazňuje funkci lexikonu, v němž každé slovo má udaný slovní druh, potřebné fráze a tématické role (explicitně zdůrazněno u sloves, ale ostatní sl. druhy to mohou používat taky). Není založena čistě na frázové struktuře, nemá transformace a projekční princip. Povrchová a hloubková struktura jsou různé:
- složková (povrchová) struktura (c-structure): typu X-bar
- funkční struktura (f-structure): jiná, z ní se odvozuje význam – předpokládá se tu podobnost mezi různými jazyky
Byla široce přijata i v Evropě, přinesla první detailní zpracování lexikonu. Předpokládá, že věty generuje mluvčí, ne gramatika, snaží se o realistický model – aby se přiblížila tomu, co opravdu lidé provádějí při tvorbě vět.
Složková (povrchová) struktura
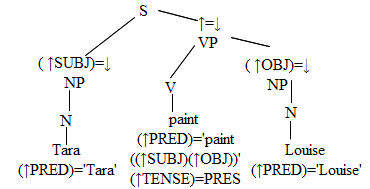
- přejímá X-bar, opět fráze a podobná pravidla jako u Chomského.
- exocentrismus: S' (klauze) nemá žádný řídící člen, jako řídící člen této složky mohou vystupovat různé „funkční řídící členy“ pro různé jazyky
- s každým frázovým pravidlem musí zůstat indikace, jak přejít na funkční strukturu (tohle bylo u Chomského dáno projekčním principem), každé pravidlo má proto funkční anotaci (ohodnocení)
- použití šipek: ↑ - odkazuje na „mateřský“ uzel (nadřízený) ↓- odkazuje na tento uzel
př. pro NP: (↑SUBJ)=↓ „subjekt nadřízeného uzlu je tento“, VP: ↑=↓ „je funkčním řídícím uzlem (obsahuje (nějakou) přímou funkční informaci o nadřízeném uzlu)“ -- toto mají všechny preterminály (tj. těsně nad konkr. slovem – N, P, V) - lexikon: slouží k přenosu funkční informace z lex. jednotek do funkční struktury spojené se složkovou
Funkční struktura a její vlastnosti

- formálně: množina dvojic rys/atribut, hodnota
- 3 druhy hodnot: symbol (PRES, SG ...), sémantická forma ('paint((↑SUBJ)(↑OBJ))'), vnořená f-struktura
- podmínky správnosti -- každý atribut má mít max. jednu hodnotu, struktura musí obsahovat všechny funkce řízené predikátem, každá řiditelná funkce musí být řízena nějakým predikátem
- přechod od složkové struktury: každá část složk. struktury má svoji část f-struktury, skládání pomocí unifikací
- Př. [NUM SG] + [PERS 3] = [NUM SG, PERS 3] - OK, [NUM SG] + [NUM PL] nelze
- subkategorizace lexikonu: podle gramatických funkcí (OBJ, SUBJ, ...), ne podle kategorií (NP, PP); predikátově-argumentová struktura (každý argument svázán s gramatickou funkcí, pro daný predikát realizován jen 1x)
- gramatické funkce: staví na Tesnièrově valenční teorii – aktanty a volná doplnění
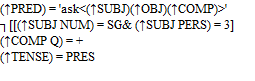
- lexikální pravidla: úpravy lex. jednotek (výsledná lex. jednotka může mít i jinou synt. strukturu), často definováno pro celou třídu lex. jednotek
- Př.: pasiv: (SUBJ) --> 0 / (OBLAG), (OBJ) --> (SUBJ), po aplikaci: (PRED)='eat<(OBLAG),(SUBJ)>'
- Spousta dalších detailů, dost podrobné
Poznámky
- „generativní gramatika“ neznamená jen „transformační“, pojem se vztahuje i na Bresnanové teorii, která transformace odmítá
- další trendy: head phrase structure grammar, TAG theory (USA, Joshy, blízké závislostní, ale také frázová struktura) a další, lokálnější (něco viz PFL012-poznámky)
* ^ ad 1 Ve skriptech je uvedené, že pravidla byla nekontextová, přímo v Chomského knize to ale není tak jednoznačné a vypadá to, že se kontextová pravidla připouští. V praktické ukázce anglické gramatiky ale jsou jen pravidla bezkontextová.
* ^ ad 2 Protože se ale pořád uplatňuje frázové dělení věty na subjektovou a slovesnou část, slovesa nemohou subkategorizovat vlastní subjekt.
Státnice -- Matematická lingvistika
Složitost a vyčíslitelnost -- Tvorba algoritmů, Odhady složitosti, NP-úplnost, Aproximační algoritmy, Vyčíslitelné funkce, Rekurzivní množiny, Nerozhodnutelné problémy, Věty o rekurzi.
Datové struktury -- Stromy, Hašování, Dynamizace, Vnější paměť, Třídění.
Formální popis jazyka -- Závislostní syntax, Frázové gramatiky, Obecná lingvistika, FGD, Formální sémantika
Statistické metody -- Korpusy, Strojové učení, Stochastické metody, Experimenty
Automatické zpracování jazyka -- Analýza jazyka, Generování jazyka, Analýza a syntéza řeči, Extrakce informací, Strojový překlad